Experiencing latency with project labeling.
Postmortem
We wanted to bring to your attention recent latency issues affecting labeler productivity on the Labelbox platform. This postmortem intends to provide you with insights on the solutions in development and rough timelines for their roll out.
Labeling Queue Latency
Over the past week, we noticed cases when the queueing system experienced degraded performance affecting labeling users’ ability to reserve and label assets. The queueing system that serves asset reservations is a distributed system that uses data row priorities and consensus settings to build queues for projects on an on-demand basis. The process used to incrementally generate the queue is generally fast, typically on the order of milliseconds, but can slow down when projects are large or when complex configurations are set.
The Labelbox team actively monitored the situation and made operational adjustments to minimize impact to customers.
While the situation has improved over the week, we recognize that this is frustrating for our customers. Therefore, we’re taking immediate action to rectify the performance issue with queuing while implementing a sound architectural solution in the near future.
Immediate Steps
We are implementing the following short-term actions to alleviate labeling queue latency. These actions will be completed within two weeks.
- Coalesce identical, duplicate requests into a single MySQL query to minimize impact to the MySQL database. As an example, since multiple users pick from the same queue to label for a project, we build the queue requested by the first user as opposed to trying to build the queue-requests from all users, simultaneously
- Rewrite the MySQL queries mentioned above for performance by minimizing the number of joins and optimizing the query plan wherever possible.
- Move these queries to a background process, thereby allowing the system to pre-compute the queue and avoid making users wait for the queue to become ready
Architectural Improvements
While the steps mentioned above address immediate latency issues, they do not help the platform truly scale to support projects that are orders of magnitude larger.
Over the next month or so, the engineering team will be implementing a data processing pipeline to pre-compute an intermediary representation of the project’s data rows. This materialized view will be structured and maintained to support computationally efficient queries that can generate pages of data rows used for populating the labeling queue.
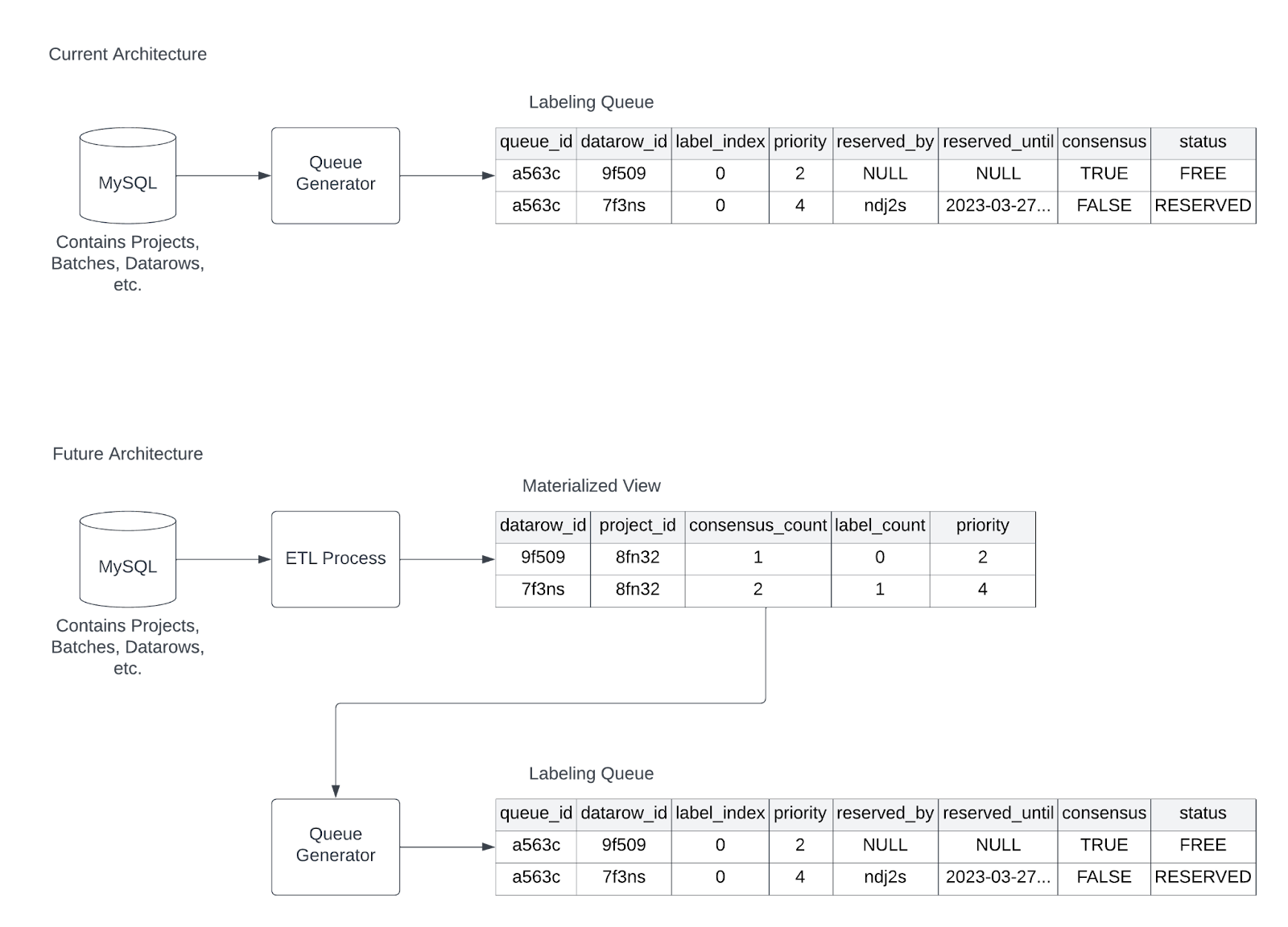
Labelbox is continuously improving platform scalability across the entire product suite, and this is one particular architectural improvement that will specifically address the current queueing latency issues. Thank you for your patience as we continue to scale the platform. We’re here to make Labelbox the most reliable and responsive platform and provide support in any way we can for your continued use.